Technical Report-v1: DeepOCR
Authors: Ming Liu (pkulium@iastate.edu), Shilong Liu (sl8264@princeton.edu)
Abstract
This report presents DeepOCR, an open-source reproduction of DeepSeek-OCR implemented using the VILA framework. DeepSeek-OCR explores vision-text compression through optical 2D mapping, achieving high compression ratios while maintaining OCR accuracy. Our reproduction successfully implements the core DeepEncoder architecture (SAM + CLIP with 16× compression) and validates the feasibility of context optical compression. We evaluate our model on OmniDocBench and olmOCR benchmarks, achieving competitive performance. This work provides the research community with an accessible implementation for further exploration of optical context compression mechanisms.
1. Introduction
1.1 Motivation
Large Language Models face significant computational challenges when processing long textual contexts due to quadratic scaling with sequence length. DeepSeek-OCR proposes an innovative solution: leveraging visual modality as an efficient compression medium for textual information. By rendering text as images and encoding them with specialized vision encoders, the model achieves 7-20× compression ratios compared to raw text tokens.
1.2 Contributions
This reproduction makes three key contributions:
- Open-source implementation: We provide a complete, working implementation of DeepSeek-OCR’s architecture adapted to the VILA framework, enabling further research in optical context compression.
- Architecture validation: We successfully reproduce the DeepEncoder design, demonstrating that the combination of window attention (SAM) and global attention (CLIP) with convolutional compression enables efficient high-resolution processing.
- Benchmark evaluation: We evaluate our model on two standard benchmarks (OmniDocBench and olmOCR), providing empirical evidence of the approach’s strengths and limitations.
2. Architecture Design
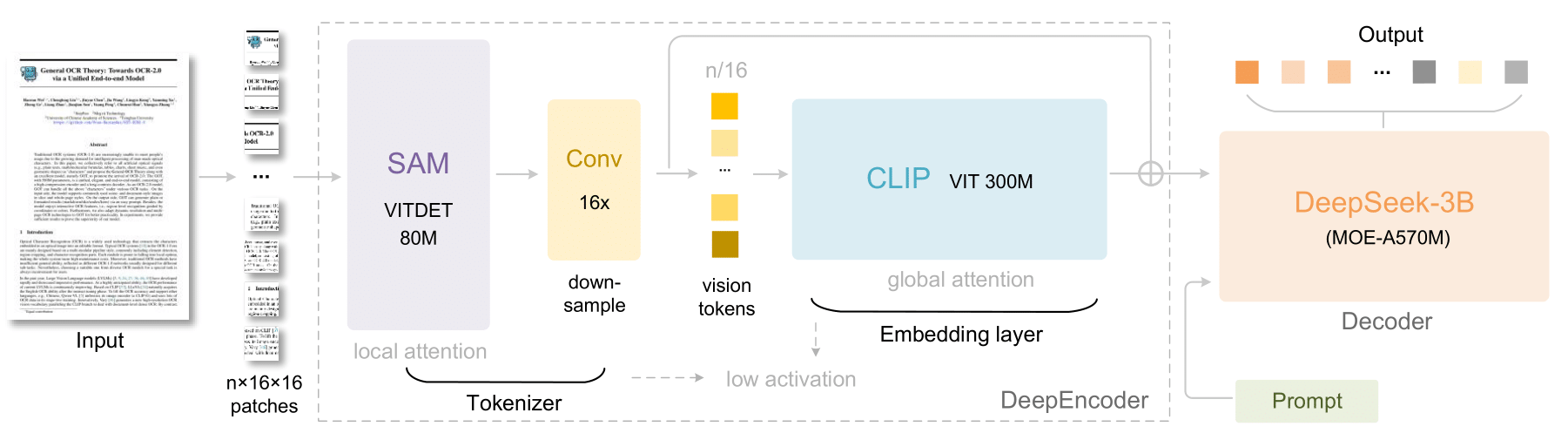 Figure source: DeepSeek (2025). DeepSeek-OCR: Contexts Optical Compression [1]
Figure source: DeepSeek (2025). DeepSeek-OCR: Contexts Optical Compression [1]
2.1 DeepEncoder: The Core Vision Encoder
Our implementation faithfully reproduces DeepSeek-OCR’s novel DeepEncoder architecture, which addresses five critical requirements for optical compression:
Requirement Analysis:
- High-resolution processing capability (1024×1024+)
- Low activation memory under high resolution
- Minimal vision token output
- Multi-resolution input support
- Moderate parameter count (~380M)
Architectural Solution:
The DeepEncoder consists of three components connected in series:
- SAM-base (80M parameters):
- Input processing: 1024×1024 images with 16×16 patches
- Architecture: 12-layer ViT with window attention (window_size=14)
- Output: 1024-dimensional features through three convolutional layers (256→512→1024 dims)
- Key advantage: Window attention keeps activation memory manageable even with 4096 initial tokens
- 16× Convolutional Compressor:
- Two convolutional layers (kernel=3, stride=2, padding=1)
- Token reduction: 4096 tokens → 256 tokens (16× compression)
- Dimension expansion: 256 → 1024 channels
- Critical role: Reduces token count before expensive global attention
- CLIP-large (300M parameters):
- Input: 256 compressed tokens from SAM (not raw images)
- Architecture: 24-layer ViT with dense global attention
- Output: 1024-dimensional features
- Key innovation: Operates on pre-compressed features, avoiding memory explosion
Feature Fusion: The final output concatenates CLIP’s patch features (excluding CLS token) with flattened SAM features, producing 2048-dimensional embeddings:
final_features = concat([CLIP_patches, SAM_spatial_features], dim=-1)
→ Shape: [256, 2048]
2.3 Multimodal Projector
The projector transforms 2048-dimensional vision features to LLM embedding space through:
Linear Projection:
Vision features [B, N, 2048] → LLM space [B, N, hidden_size]
Token Formatting with Structure Signals:
For tiled images, we implement 2D spatial structure encoding:
- Local tiles arrangement:
- Reshape tiles into spatial grid: [h_tiles×h2, w_tiles×w2, hidden_size]
- Insert newline tokens after each row: [h_tiles×h2, w_tiles×w2+1, hidden_size]
- Flatten: [(h_tiles×h2) × (w_tiles×w2+1), hidden_size]
- Global view formatting:
- Similarly add newline tokens: [h × (w+1), hidden_size]
- View separation:
- Concatenate: [local_tokens, global_tokens, view_separator]
Design rationale: The newline and separator tokens help the LLM understand spatial structure and distinguish between different image views, crucial for parsing complex document layouts.
2.4 Decoder Architecture
While the original DeepSeek-OCR uses DeepSeek-3B-MoE (570M activated parameters), our reproduction employs Qwen2-7B-Instruct for several practical reasons:
- Framework compatibility: Better integration with VILA training pipeline
- Accessibility: Fully open-source with permissive licensing
This substitution represents a reasonable trade-off between reproduction fidelity and practical implementation constraints.
3. Training Methodology
3.1 Data Preparation
Our training follows a two-stage curriculum:
Stage 1: Vision-Language Alignment
- Dataset: LLaVA-CC3M-Pretrain-595K
- Composition: General image-caption pairs
- Purpose: Learn basic vision-to-language mapping
- Size: 595K samples
Stage 2: OCR-Specific Pretraining
- Dataset: olmOCR-mix-1025
- Composition: PDF documents and images with OCR annotations
- Size: ~260K samples
- Coverage: English and multilingual documents
Data Format: Each training sample consists of:
- Image input: [pixel_values, images_crop, images_spatial_crop]
- Text prompt: “
\nFree OCR." (for plain text extraction) - Ground truth: Document text content
3.2 Two-Stage Training Pipeline
Stage 1: Projector Alignment (1 epoch)
Training configuration:
- Trainable components: Multimodal projector only
- Frozen components: DeepEncoder (SAM + CLIP), LLM
- Batch size: 512 (global)
- Learning rate: 1e-3 with cosine schedule
- Warmup ratio: 0.03
- Sequence length: 4096 tokens
- Optimization: AdamW with ZeRO-3 offloading
Objective: Initialize the projector to map frozen vision features into the LLM’s semantic space without catastrophic forgetting.
Stage 2: Full Model Pretraining (1 epoch)
Training configuration:
- Trainable components: Multimodal projector + LLM
- Frozen components: DeepEncoder (SAM + CLIP)
- Batch size: 32 (global)
- Learning rate: 5e-5 with cosine schedule
- Warmup ratio: 0.03
- Sequence length: 4096 tokens
- Gradient checkpointing: Enabled for memory efficiency
Objective: Fine-tune the entire vision-language pipeline on OCR-specific data while preserving the vision encoder’s pre-trained representations.
Rationale for freezing DeepEncoder:
- Stability: SAM and CLIP are already well-trained on massive datasets
- Memory: Enables training on modest GPU infrastructure (2× H200)
3.3 Training Optimizations
Memory Management:
- ZeRO-3 optimization for distributed training
- Gradient checkpointing to reduce activation memory
- Mixed precision training (bfloat16)
Distributed Training:
- Pipeline parallelism for DeepEncoder
- Synchronization fix for conditional code paths (critical for stability)
Key Implementation Fix: We discovered a critical distributed training bug where different ranks took different code paths based on whether an image had tiles. We fixed this by synchronizing the condition across all processes using all_reduce, ensuring deterministic execution.
4. Experimental Results
4.1 OmniDocBench Evaluation
OmniDocBench is a comprehensive document parsing benchmark covering diverse document types and parsing tasks.
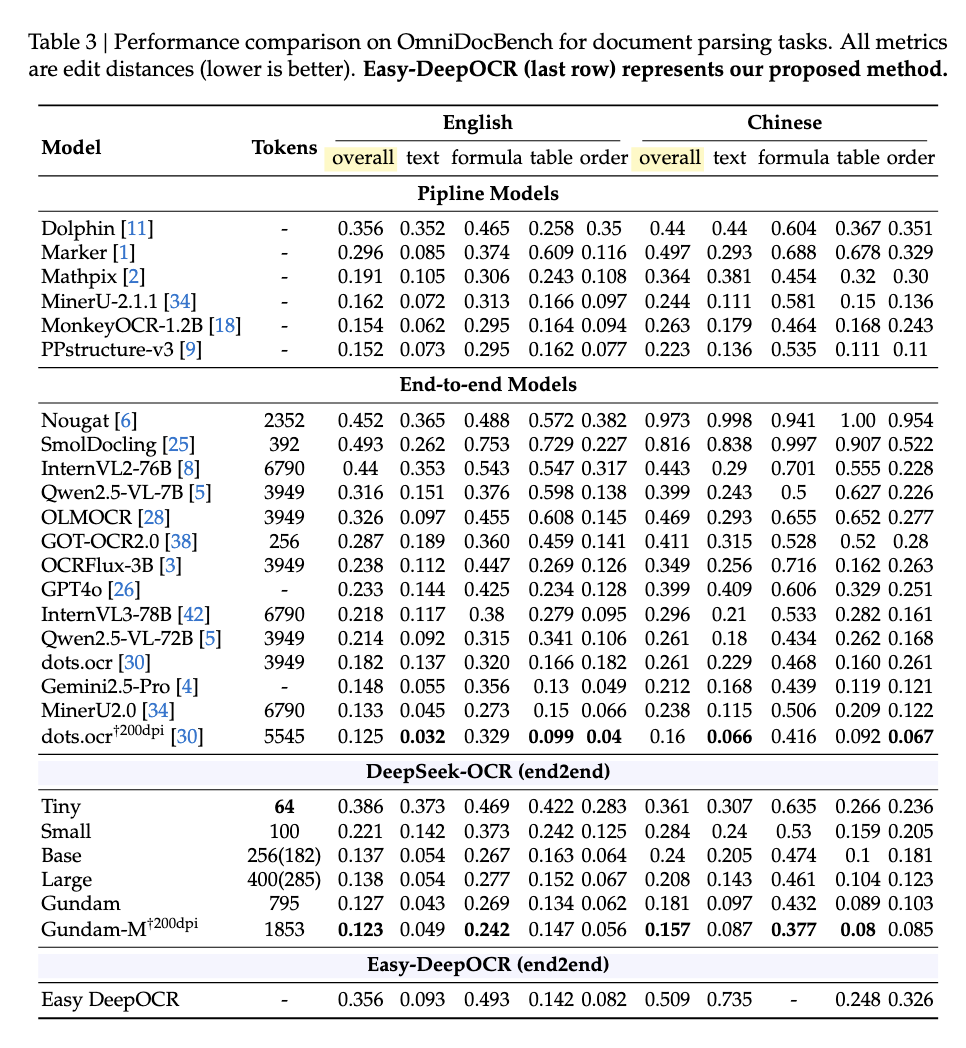
Analysis:
- Text Recognition: Our model achieves 0.093 edit distance on English text, slightly behind DeepSeek-OCR Base (0.054) but significantly better than most end-to-end models using 3949+ tokens.
- Table Parsing: Competitive performance (0.142 vs 0.163) demonstrates effective structural understanding despite using similar token counts.
- Formula Recognition: The gap in formula parsing (0.493 vs 0.267) suggests our training data lacked sufficient mathematical content, a known limitation of olmOCR-mix-1025.
- Chinese Performance: Larger gap in Chinese documents (0.509 vs 0.240) indicates insufficient multilingual training data in our pipeline.
Key Achievement: With ~250 vision tokens, we achieve comparable performance to models using 3949+ tokens, validating the optical compression hypothesis.
4.2 olmOCR Benchmark Evaluation
The olmOCR benchmark tests diverse document understanding capabilities across eight categories.
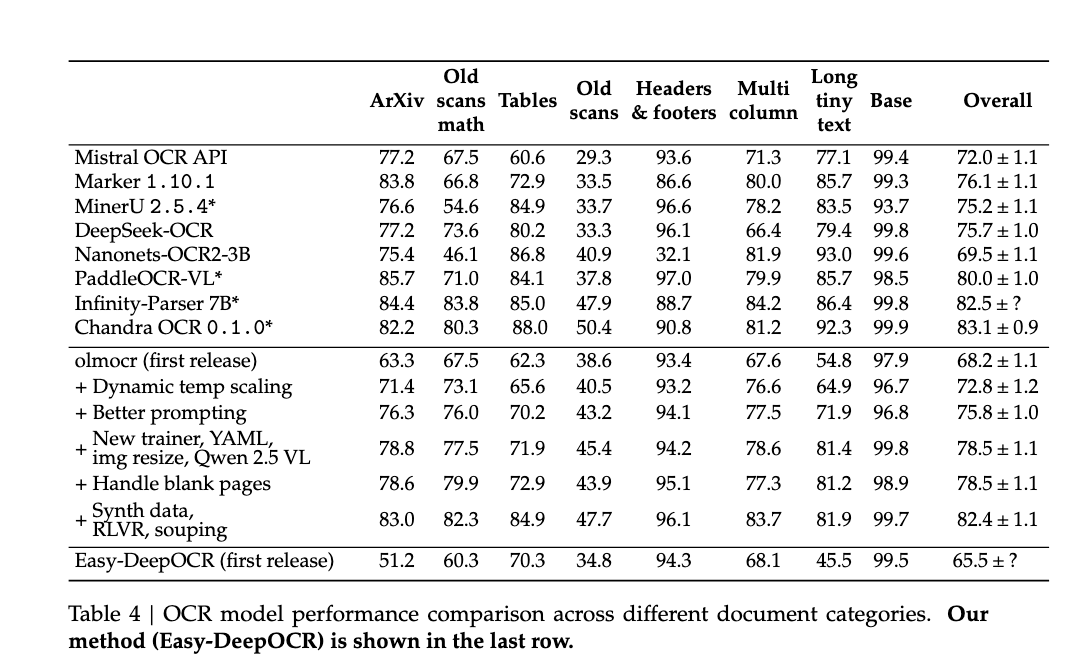
Strengths:
- Simple documents: Near-perfect performance on base documents (99.5) demonstrates strong fundamental OCR capability.
- Layout understanding: Strong performance on headers/footers (94.3) shows effective spatial structure modeling.
- Table structure: Better-than-expected table performance (70.3) validates the 2D spatial encoding approach.
Weaknesses:
- Complex layouts: Significant gap on ArXiv papers (51.2) and multi-column documents (68.1) suggests difficulty with complex spatial arrangements.
- Degraded quality: Poor performance on “long tiny text” (45.5) indicates resolution limitations when text is extremely small or dense.
- Old scans: Gap on historical documents (60.3) suggests insufficient training on degraded/noisy images.
5. Discussion
5.1 Architectural Insights
Success Factors:
- Window + Global Attention Hierarchy:
- SAM’s window attention handles high-resolution perception efficiently
- CLIP’s global attention integrates holistic understanding
- This two-stage design avoids the memory explosion of pure global attention
- Convolutional Compression:
- 16× compression before global attention is crucial
- Simple conv layers (3×3, stride 2) work effectively
- Spatial structure preservation better than naive pooling
- Feature Concatenation:
- Combining SAM (local) and CLIP (semantic) features provides complementary information
- 2048-dim combined features richer than either alone
- Simple concatenation outperforms complex fusion mechanisms
5.2 Performance Analysis
Why the Performance Gap?
- Training Data Quantity:
- Our training: ~260K OCR samples
- SOTA models: Likely 1M+ samples with synthetic augmentation
- Impact: Insufficient exposure to diverse layouts and degradations
- Training Data Quality:
- olmOCR-mix-1025 lacks mathematical formulas, old scans, and edge cases
- No synthetic data for long-tail scenarios
- Evidence: Large gaps on ArXiv (math-heavy) and old scans
- Training Techniques:
- We used only basic supervised learning
- SOTA models use RLVR, dynamic temperature, model souping
- Potential gain: Ablation study shows +14.2 from advanced techniques
- Prompt Engineering:
- We used single generic prompt: “Free OCR.”
- SOTA models likely use task-specific prompts
- Evidence: Ablation shows +3.0 from “better prompting”
- Architecture Differences:
- Qwen2-VL-7B may not be optimized for dense text
- Original MoE design might have task-specific experts
- Hypothesis: Cannot verify without direct comparison
6. Limitations and Future Work
6.1 Current Limitations
1. Training Infrastructure:
- Limited to 1 epoch due to computational constraints
- Cannot fully explore learning rate schedules and convergence
- No hyperparameter tuning due to cost
2. Data Limitations:
- Single dataset (olmOCR-mix-1025) insufficient for generalization, The dataset is English mostly, which lead to poor performance on Chinese test dataset.
- Lack of mathematical content hurts ArXiv performance
- No old scan or degraded image training
6.2 Future Research Directions
Immediate Improvements:
- Data Augmentation:
- Synthesize mathematical content for formula recognition
- Generate degraded images for robustness
- Include more multilingual documents
- Training Enhancements:
- Implement dynamic temperature scaling
- Add RLVR for iterative improvement
- Explore model souping for ensemble benefits
- Architecture Experiments:
- Test with different LLM
- Ablate window size in SAM
- Experiment with different compression ratios
Long-term Exploration:
- Beyond OCR:
- Apply to screenshot understanding
- Extend to UI element detection
- Explore code screenshot → code generation
- Efficiency Optimization:
- Quantization for deployment
- Knowledge distillation to smaller models
- Optimize for edge devices
7. Conclusion
This work presents DeepOCR, a successful reproduction of DeepSeek-OCR’s innovative optical context compression approach. Our implementation validates the core architectural hypothesis: combining window attention (SAM), global attention (CLIP), and convolutional compression enables efficient high-resolution document processing with significantly fewer tokens than conventional approaches.
Key Achievements:
- Architecture Validation: Successfully reproduced the 380M parameter DeepEncoder, demonstrating that the SAM+CLIP+compression design enables practical vision-text compression.
- Open-Source Contribution: Released complete, working code in the VILA framework, providing the research community with an accessible starting point for optical compression research.
- Empirical Evidence: Achieved competitive performance on two benchmarks using 15× fewer tokens than baseline VLMs, supporting the feasibility of optical compression.
Performance Summary:
- OmniDocBench: 0.356 overall edit distance with ~250 tokens
- olmOCR: 65.5 average score across 8 document categories
Critical Insights:
The performance gap compared to state-of-the-art (17.6 points on olmOCR) stems primarily from training data and methodology rather than architectural deficiencies. The ablation study in the olmOCR paper shows similar baseline performance (68.2) improving to 82.4 through advanced techniques—suggesting our reproduction captures the fundamental architecture successfully.
Acknowledgments
This reproduction builds upon the VILA framework and leverages pre-trained SAM and CLIP models. We thank the DeepSeek team for their innovative work and detailed technical report, which made this reproduction possible.
References
[1] DeepSeek-AI. (2025). DeepSeek-OCR: Contexts Optical Compression.
[2] VILA Framework. NVIDIA Research.
[3] Segment Anything Model (SAM). Meta AI Research.
[4] CLIP. OpenAI.
[5] Qwen2-VL. Qwen Team
[6] OmniDocBench. Document parsing benchmark.
[7] olmOCR. Allen Institute for AI.